做 RAG 的都知道一个铁律:向量搜索的速度和内存占用,直接决定了整个系统的成本和体验。FAISS 是行业标杆没错,但它的 IndexPQ 需要预训练、参数调优、数据量大起来内存也撑不住。
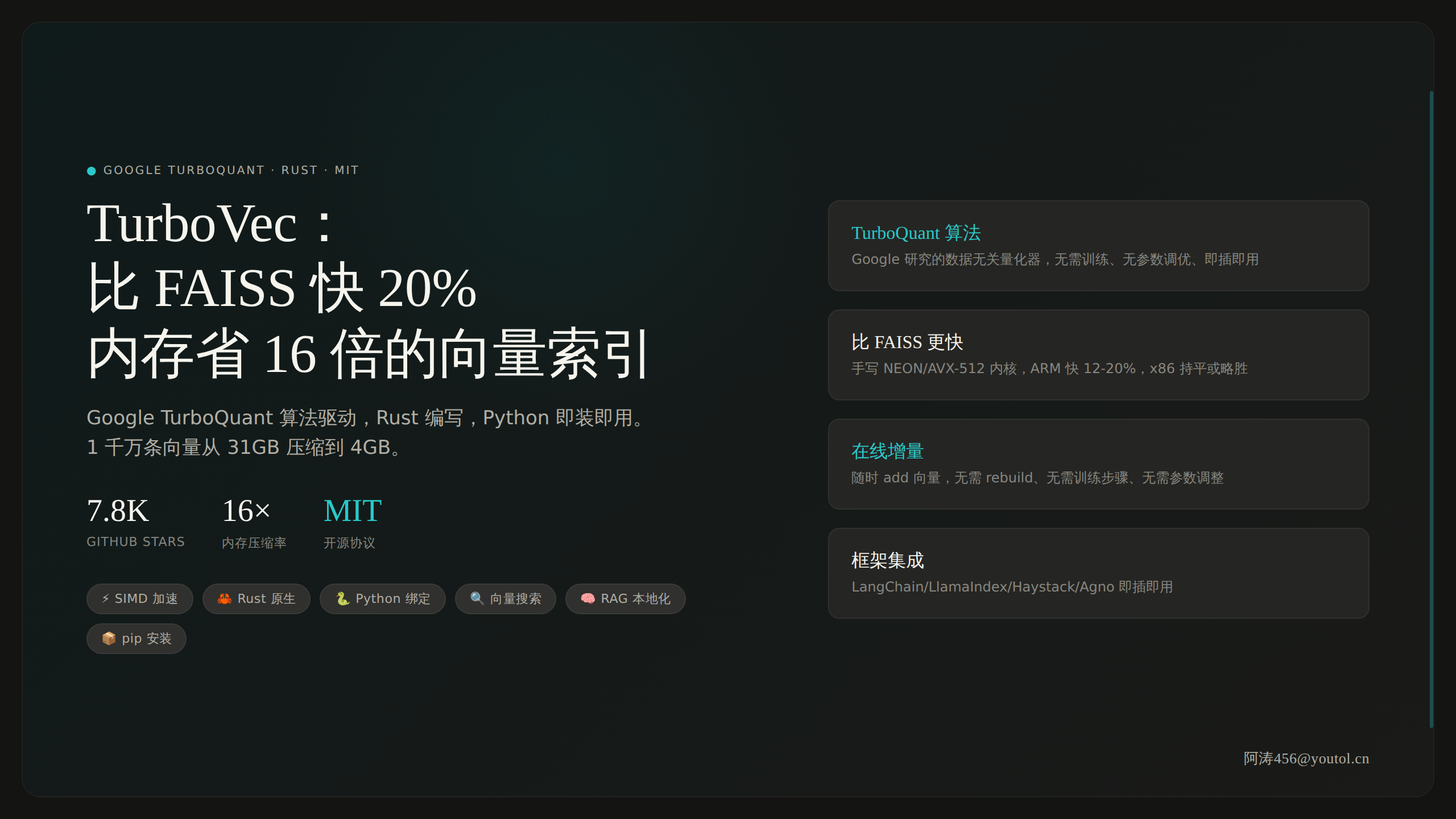
TurboVec 是一个新的向量索引库,基于 Google Research 的 TurboQuant 算法。Rust 写的,有 Python 绑定,主打三个字:快、省、零调优。GitHub 上 7.8K Stars,今年 3 月才开源,三个月冲到这么多,说明什么?说明向量搜索这个领域太需要更好的方案了。
是什么
TurboVec 是一个基于 Google TurboQuant 算法的向量索引。核心思路是一种叫做「数据无关量化器」(data-oblivious quantizer)的技术——和 FAISS 的 PQ(乘积量化)完全不同,它不需要对数据分布做任何假设,也不需要单独的训练阶段。
16 倍压缩 —— 官方给了一个很直观的数据:1 千万条向量(dim=1536),存成 float32 要 31GB RAM,TurboVec 只需要 4GB。16 倍压缩率,召回率几乎不掉。
比 FAISS 快 —— 手写了 NEON(ARM)和 AVX-512BW(x86)的 SIMD 内核,在 ARM 上比 FAISS IndexPQFastScan 快 12-20%,x86 上持平或略胜。
零训练步骤 —— FAISS 的 PQ 需要先跑一遍训练数据才能建索引。TurboVec 不需要。直接把向量 add 进去就能搜索,加新向量也不需要 rebuild。这对于动态增长的数据集非常友好。
搜索时过滤 —— 支持传一个 id allowlist,搜索时只在允许的集合里找,不会先全量搜索再裁剪。过滤逻辑嵌在 SIMD 内核层面,效率极高。
框架集成 —— LangChain、LlamaIndex、Haystack、Agno 都有现成的集成。pip install turbovec[langchain] 直接替换内存向量存储。
安装和使用
安装只需要一行:
pip install turbovec
基础使用:
from turbovec import TurboQuantIndex
# 建索引
index = TurboQuantIndex(dim=1536, bit_width=4)
index.add(vectors)
# 搜索
scores, indices = index.search(query, k=10)
# 持久化
index.write("my_index.tq")
loaded = TurboQuantIndex.load("my_index.tq")
如果需要稳定的外部 ID 和删除支持:
from turbovec import IdMapIndex
index = IdMapIndex(dim=1536, bit_width=4)
index.add_with_ids(vectors, np.array([1001, 1002, 1003]))
scores, ids = index.search(query, k=10)
index.remove(1002) # O(1) 删除
还有 pg_turbovec —— 一个 PostgreSQL 扩展,把 TurboVec 直接集成到 Postgres 里做向量搜索。
为什么值得关注
当前向量数据库/索引领域有个问题:要不就是太重(Milvus、Weaviate 要单独部署服务),要不就是内存占用太大(FAISS float32 索引),要不就是体验不好(需要预训练、调参)。TurboVec 在「轻量 + 省内存 + 零调优」这个三角上做到了很好的平衡。
特别适合的场景:
本地 RAG —— TurboVec + Ollama,完全在本地跑,不依赖任何外部服务。
单机应用 —— 桌面应用、嵌入式设备,内存有限但需要向量搜索。
动态数据集 —— 数据不断增长,不想每次加数据都 rebuild 索引。
隐私敏感的场景 —— 数据不出本机,也不需要调用云端的向量数据库 API。
不是没有槽点
说几个实话。
项目太新了 —— 2026 年 3 月才创建,才 3 个月。社区、文档、生态都还在早期。虽然 API 设计得很干净,但生产环境大规模使用需要多观察。
只有暴力搜索 + 量化 —— TurboVec 目前是扁平索引 + 量化搜索,不支持 IVF 或 HNSW 这类近似索引结构。对于超大超大规模的数据集(百万级以上全量搜索),性能可能不如有索引结构的方案。
SIMD 指令集依赖 —— 高性能依赖 AVX-512BW(x86)或 NEON(ARM)。旧 CPU 没有这些指令集的话,会回退到通用实现,速度优势就小了。
生态还小 —— FAISS 有十几年的积累,各种索引类型、各种优化手段。TurboVec 目前就是单一的 TurboQuant 索引,功能上还比较单一。
跟同类怎么比
vs FAISS:FAISS 功能全、索引类型多、工业验证充分。TurboVec 在单个场景(PQ 类索引)上做得更好(更快 + 更省内存 + 无需训练)。大型生产系统用 FAISS,轻量场景用 TurboVec。
vs sqlite-vec:之前介绍过 sqlite-vec,也是轻量向量搜索。sqlite-vec 的优势是 SQLite 集成、嵌入式。TurboVec 的优势是性能(SIMD 优化 + 16x 压缩),适合更大规模的数据集。
vs 专业向量数据库:Pinecone / Weaviate / Milvus 适合分布式、多云、大规模场景。TurboVec 是单机库,定位完全不同。
一句话:如果你做本地 RAG 或者单机向量搜索,在意内存占用和搜索速度,TurboVec 是目前最值得关注的新方案。尤其那个"零训练、在线 add、16x 压缩"的组合,用过的都说爽。
GitHub:github.com/RyanCodrai/turbovec
论文:arxiv.org/abs/2504.19874 (TurboQuant)
PyPI:pypi.org/project/turbovec/
标签:#TurboVec #向量搜索 #TurboQuant #RAG #FAISS替代 #Rust #本地AI #SIMD
关注我,每期分享一个帮你省事的强大工具 🛠️